
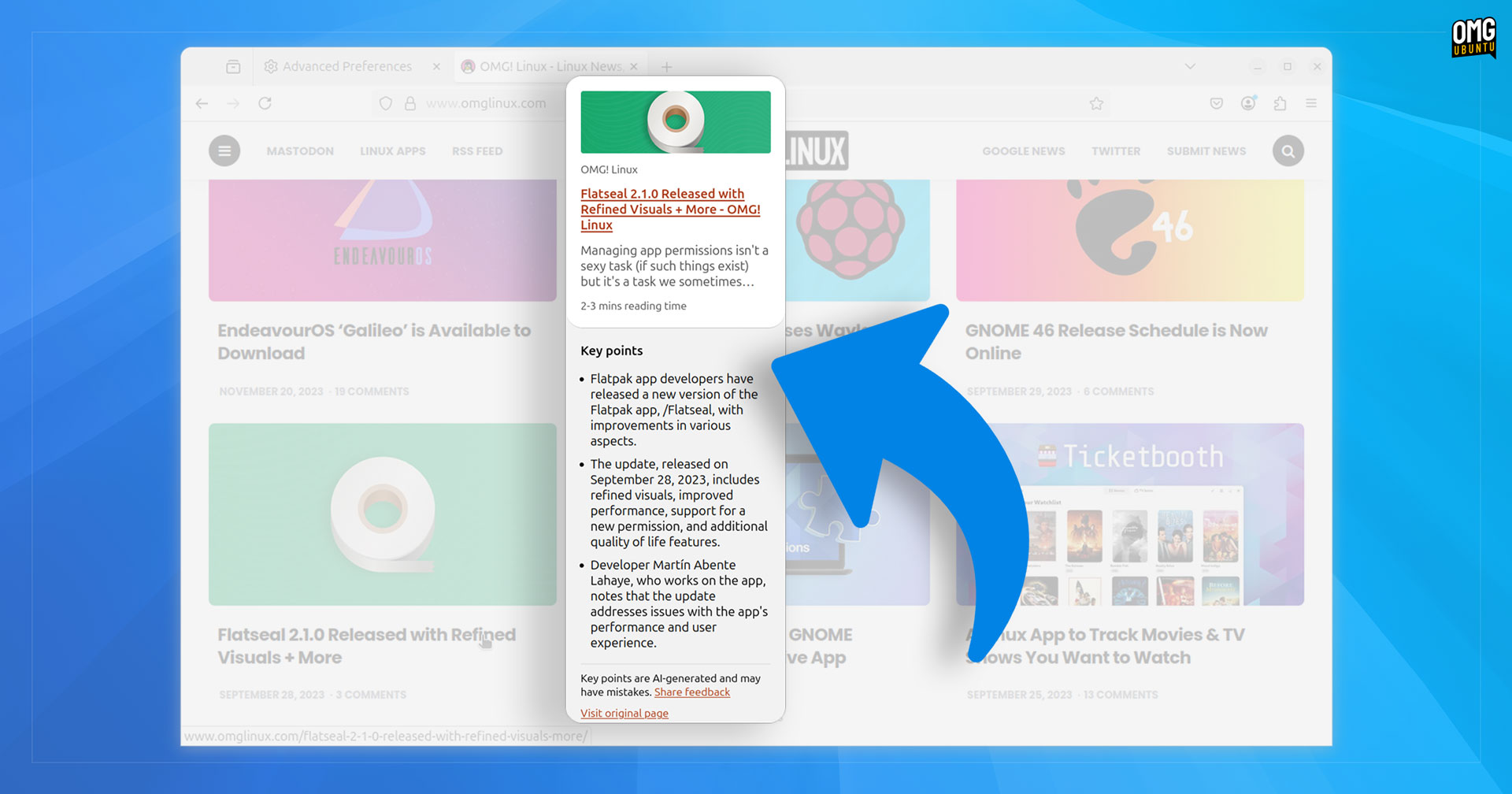
Latest nightly builds of Firefox 139 include an experimental web link preview feature which shows (among other things) an AI-generated summary of what that page is purportedly about before you visit it, saving you time, a click, or the need to ‘hear’ a real human voice.
Hate having to read an article to understand what it’s saying and would rather read what an AI says it (potentially) says instead?
This reads like satire.
Maybe because it is, an article says later “Saltiness aside” 😏
Oh! That makes more sense lol
this is the next step from just reading headlines and getting everything wrong
deleted by creator
Ideally it would do that for links. As in, hover and it gives like a 2-sentence summary. In your example, the summary could say something like:
Cashews are pretty good for you, but almonds are better. The article discusses micronutrient differences between the two.
Or something like that.
Hell yeah! My local news sites always go on and on about stupid stuff before getting to the point. Which is almost always “we don’t know”.
If it works around paywalls, it could actually be a useful feature.
It reportedly works entirely on your machine (as it meant to be privacy preserving by default). So it will probably see only the data you can see.
Awesome! Now half the sites on the web contain a tiny drop of information, buried under paragraphs and paragraphs of GPT-generated text, and now my browser uses the same LLM to reverse engineer the original information. What could possibly go wrong the LLMs talk to other LLMs and summarize, bloat, summarize and then bloat and then finally summarize every bit of information for us.
Do we actually still make websites for humans, or is it all just AIs and SEO?
Copy-paste from the Arc browser. It’s a hit-or-miss feature; it works 50% of the time.
I wonder if the preview does a pre-fetch which can be identified as such? As in, I wonder if I’d be able to serve garbage for the AI summarizer, but the regular content to normal views. Guess I’ll have to check!
Update: It looks like it sends an
X-Firefox-Ai: 1header. Cool. I can catch that, and deal with it.Alternatively, you could make your response more useful, removing the UI to aid the AI. After all, the user should be allowed to choose how they navigate the web.
I am doing exactly that. AI turns my work into garbage, so I serve them garbage in the first place, so they have less work to do. I am helping AI!
I’m also helping AI using visitors: they will either stop that practice, or stop visiting my stuff. In either case, we’re both better off.
I agree with your sentiment. It’s sad that your (or my) website can’t respond with a
X-This-Website-is-not-AI-Garbageheader to indicate that “Hey user, you can actually just open this website and read it and get the infos you need without an AI assistant.”.I’m pretty sure Firefox’s preflight request will also not load ads and so could be seen as a bad scraper.
User agents that /look/ legit, but the chances of someone using them /today/ is highly unlikely.
I hope I’ll never need to deal with websites administered by you. This is way overboard.
Sajnos az esélye nem olyan kicsi mint azt szeretném.Overboard? Because I disallow AI summaries?
Or are you referring to my “try to detect sketchy user agents” ruleset? Because that had two false positives in the past two months, yet, those rules are responsible for stopping about 2.5 million requests per day, none of which were from a human (I’d know, human visitors have very different access patterns, even when they visit the maze).
If the bots were behaving correctly, and respected my
robots.txt, I wouldn’t need to fight them. But when they’re DDoSing my sites from literally thousands of IPs, generating millions of requests a day, I will go to extreme lengths to make them go away.Overboard? Because I disallow AI summaries?
you disallow access to your website, including when the user agent is a little unusual. do you also only allow the last 1 major version of the official versions of major browsers?
yet, those rules are responsible for stopping about 2.5 million requests per day,
nepenthes. make them regret it
you disallow access to your website
I do. Any legit visitor is free to roam around. I keep the baddies away, like if I were using a firewall. You do use a firewall, right?
when the user agent is a little unusual
Nope. I disallow them when the user agent is very obviously fake. Noone in 2025 is going to browse the web with “Firefox 3.8pre5”, or “Mozilla/4.0”, or a decade old Opera, or Microsoft Internet Explorer 5.0. None of those would be able to connect anyway, because they do not support modern TLS ciphers required. The rest are similarly unrealistic.
nepenthes. make them regret it
What do you think happens when a bad agent is caught by my rules? They end up in an infinite maze of garbage, much like the one generated by nepenthes. I use my own generator (iocaine), for reasons, but it is very similar to nepenthes. But… I’m puzzled now. Just a few lines above, you argued that I am disallowing access to my website, and now you’re telling me to use an infinite maze of garbage to serve them instead?
That is precisely what I am doing.
By the way, nepenthes/iocaine/etc alone does not do jack shit against these sketchy agents. I can guide them into the maze, but as long as they can access content outside of it, they’ll keep bombarding my backend, and will keep training on my work. There are two ways to stop them: passive identification, like my sketchy agents ruleset, or proof-of-work solutions like Anubis. Anubis has the huge downside that it is very disruptive to legit visitors. So I’m choosing the lesser evil.
Definitely won’t be visiting your website then if you intentionally fuck with people to make their browsing experience worse. I hate web hosters who are against the free and open internet.
Pray tell, how am I making anyone’s browsing experience worse? I disallow LLM scrapers and AI agents. Human visitors are welcome. You can visit any of my sites with Firefox, even 139 Nightly, and it will Just Work Fine™. It will show garbage if you try to use an AI summary, but AI summaries are garbage anyway, so nothing of value is lost there.
I’m all for a free and open internet, as long as my visitors act respectfully, and don’t try to DDoS me from a thousand IP addresses, trying to train on my work, without respecting the license. The LLM scrapers and AI agents do not respect my work, nor its license, so they get a nice dose of garbage. Coincidentally, this greatly reduces the load on my backend, so legit visitors can actually access what they seek. Banning LLM scrapers & AI bots improves the experience of my legit visitors, because my backend doesn’t crumble under the load.
LLM scrapers? What are you on about? This feature will fetch the page and summarize it locally. It’s not being used for training LLMs. It’s practically like the user opened your website manually and skimmed the content. If your garbage summary doesn’t work I’ll just copy your site and paste it in ChatGPT to summarize it for me. Pretty much the equivalent of what this is.
AI summaries are garbage anyway, so nothing of value is lost there.
Your ignorance annoys me. It has value to a lot of people including me so it’s not garbage. But if you make it garbage intentionally then everyone will just believe your website is garbage and not click the link after reading the summary.
This feature will fetch the page and summarize it locally. It’s not being used for training LLMs.
And what do you think the local model is trained on?
It’s practically like the user opened your website manually and skimmed the content
It is not. A human visitor will skim through, and pick out the parts they’re interested in. A human visitor has intelligence. An AI model does not. An AI model has absolutely no clue what they user is looking for, and it is entirely possible (and frequent) that it discards the important bits, and dreams up some bullshit. Yes, even local ones. Yes, I tried, on my own sites. It was bad.
It has value to a lot of people including me so it’s not garbage.
If it does, please don’t come anywhere near my stuff. I don’t share my work only for an AI to throw away half of it and summarize it badly.
But if you make it garbage intentionally then everyone will just believe your website is garbage and not click the link after reading the summary.
If people who prefer AI summaries stop visiting, I’ll consider that as a win. I write for humans, not for bots. If someone doesn’t like my style, or finds me too verbose, then my content is not for them, simple as that. And that’s ok, too! I have no intention of appealing to everyone.
A human using a browser feature/extension you personally disapprove of does not make them a bot. Once your content is inside my browser I have the right to disrespect it as I see fit.
Not that I see much value in “AI summaries” of course - but this feels very much like the “adblocking is theft” type discourse of past years.
A human using a browser feature/extension you personally disapprove of does not make them a bot
So…? It is my site. If I see visitors engaging in behaviour I deem disrespectful or harmful, I’ll show them the boot, bot or human. If someone comes to my party, and starts behaving badly, I will kick them out. If someone shows up at work, and starts harassing people, they will be dealt with (hopefully!). If someone starts trying to DoS my services, I will block them.
Blocking unwanted behaviour is normal. I don’t like anything AI near my stuff, so I will block them. If anyone thinks they’re entitled to my work regardless, that’s their problem, not mine. If they leave because my hard stance on AI, that’s a win.
Once your content is inside my browser I have the right to disrespect it as I see fit.
Then I have the right to tell you in advance to fuck off, and serve you garbage! Good, we’re on the same page then!
This feels like windows recall…
Except without the shitty parts where it keeps a log of everything you do and sends it off your device, luckily.
Well, it is sending it off your device to the AI’s API. Luckily it won’t have any id information, such as cookies, screen size, OS, IP, etc.
The problem seems to be with the word luckily.
Huh? The article says:
it is generated locally, on your device
Did I misread something?
(Agreed that this should be the norm and not luck.)
You didn’t misread. It says something along the lines that being generated locally takes long, and that it could be faster to read the article and summarize it yourself.
Then, there’s the inconvenience of having a small LLM instance installed locally: being small means it’s not very effective, but “small” is not really small… So what could the future bring us?
Exactly! The convenience of a big LLM, that is fast, that is more accurate, at the relative small cost of not being hosted locally. It’s a slippery slope, and as LLMs evolve (both in effectiveness and size), I think we know where it all ends.
Ah OK, so it just feels like Windows Recall if we assume it’s going to become Windows Recall in the future…




